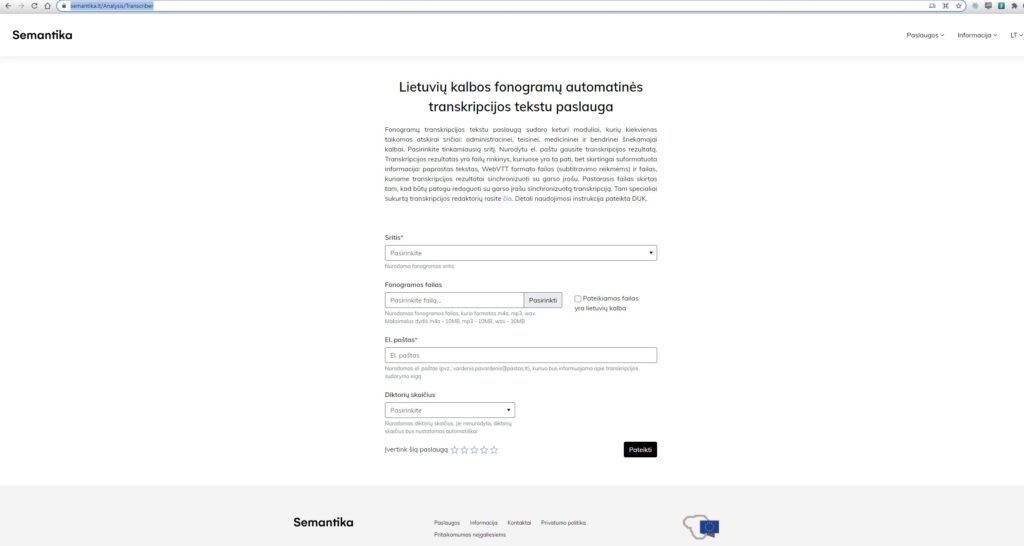
Kur galima rasti sprendimą: https://www.semantika.lt/ ; https://www.semantika.lt/Analysis/Transcriber
Kodėl ir kaip?
Mūsų sprendimas lietuvių šnekos įrašo failą (fonogramą) automatiškai transkribuoja (perrašo) lietuvių kalbos tekstu ir vartotojui grąžina tris rezultatus (failus): 1) sintaksiškai ir gramatiškai sutvarkytą fonogramos transkripciją, kurioje tekstas suskaidytas pagal kalbėtojus (jei yra keli kalbėtojai); 2) sinchronizacijos failą, kuri leidžia vartotojui transkripciją patogiai redaguoti mūsų parengtame transkripcijų redaktoriuje; 3) tarptautinius standartus atitinkančią subtitravimo failą, kurios pagalba galima sutitruoti vaizdo įrašą, kurio garso takelis buvo transkribuotas mūsų sprendimu. Sprendimas gali transkribuoti neribotos apimties, laisvai formuluojamos lietuvių kalbos fonogramas. Internete pateikta paslaugos versija, teikiama per vartotojo grafinę sąsają, dėl įvairių priežasčių priima ribotos apimties rinkmenas. Vartotojas, norintis apdoroti neribotus duomenų masyvus ir/arba norintis apsaugoti fonogramose esančias tarnybines paslaptis/jautrius duomenis (pvz.: advokatų kontoros, sveikatos priežiūros įstaigos), mūsų sprendimą gali patogiai įsidiegti ir nemokamai naudoti savo įmonės/organizacijos informacinėje sistemoje. Kuriant šnekos atpažinimo ir tranksribavimo tekstu sprendimą, buvo išspręsta daug MTEP uždavinių iš kurių svarbiausi yra šie: 1) buvo ištirti ir sudaryti HMM (Paslėpti Markovo modeliai), TDNN (angl. Time-Delay Neural Network), BLSTM (Rekurentinių neuroninių tinklų modifikacija angl. Bidirectional Long Short Term Memory), CNN (Sąsūkio neuroninis tinklas angl. Convolutional Neural Network) tipo lietuvių kalbos akustiniai modeliai ir pasirinktas modelis leidžia pasiekti didžiausią šnekos atpažinimo tikslumą; 2) buvo ištirtos ir sudarytos įvairios dekoderio architektūros, įskaitant “end-to-end” principu veikiančią dirbtinių neuroninių tinklų ir hibridinę dirbtinių neuroninių tinklų – paslėptų Markovo modelių architektūras; 3) buvo sukurtas ir sukonstruotas specializuotas konverteris, atsižvelgiantis į lietuvių kalbos kirčiavimo dėsningumus; 4) buvo sukurtas ir sukonstruotas nuosavas VAD (šnekos įvykio aptikimas (angl. voice activity detection)) metodas, garso įraše atpažįstantis dviejų tipų segmentus (tyla/šneka); 5) buvo sukurtas ir sukonstruotas rašytinės kalbos normalizavimo sprendimas, kuriuo siekiama priartinti rašytinę kalbą prie šnekamosios kalbos stiliaus (transkripcijos normalizavimo etapas prieš pateikiant ją vartotojui); 6) buvo sukurta metodologija, leidžianti greitai ir efektyviai rinkti audio resursus – balso pavyzdžius ir juos tinkamai anotuoti, automatiškai atpažinti netiksliai ekspertų anotuotus įrašus ir juos eliminuoti iš akustinio modelio mokymo proceso – taip sumažinant duomenų triukšmą ir padidinant akustinio modelio tikslumą; 7) pradinis sprendimo variante naudojamas lietuvių kalbos modelis atpažino 1,5 mln. žodžių formų, bet žodynas nuolat pildomas. Aprašytų technologinių sprendimų dėka pavyko pasiekti aukštą tikslumą, aukštą kokybę ir vartotojo poreikius tenkinančią sprendimo greitaveiką.
Kuo išskirtinis?
ATRA sprendimo išskirtinumai: 1. Kokybė. Sprendimą rengė ilgametę patirtį turinti informatikų ir kalbininkų komanda. Todėl mūsų sprendimas šiuo metu yra vienas iš kokybiškiausių (auščiausią tikslumą turinčių) lietuvių kalbos šneką transkribuojantis kokybišku lietuvišku tekstu sprendimų. 2. Skirta apdoroti neribotos apimties laisvai formuluojamą lietuvių šneką bendrinės, medicinos ir teisinės kalbos srityse. Tuo skiriasi nuo diktavimo sprendimų, kurie orientuoti į trumpų frazių atpažinimą. 3. Prieš pateikiant tranksribuotą tekstą vartotojui, jis papildomai sutvarkomas, panaudojant specialiai tam sukurtą lietuvių kalbos modelį. Todėl vartotojui pateikiamas tekstas yra gramatiškai sutvarkytas ir suskaidytas į semantiškai bei struktūriškai prasmingus vienetus (sakinius). T.y., vartotojui pateikiamas sutvarkytas lietuviškas tekstas. 4. Vartotojui pateikiamas patogus, nemokamas transkripcijų redaktorius, kuris leidžia patogiai redaguoti transkripciją, reikalui esant išklausant tik vartotojui abejones sukėlusią fonogramos vietą. Tai ypač patogu redaguojant ilgos fonogramos transkripciją. 5. Sprendimas ir jo visos jo teikiamos paslaugos yra nemokamos (per vartotojo grafinę sąsają, sąsaja mažina-mažina, transkripcijų redaktorius, vartotojo sistemoje diegiamas arba kuriamoje paslaugoje panaudojamas sprendimo programinis kodas). 6. Technologinis sprendimas patalpintas tarptautinius standartus atitinkančiuose Docker konteineriuose. Tai leidžia technologinį sprendimo variantą patogiai diegti ir panaudoti savo sistemose ir/arba naujai kuriamose paslaugose. Sprendimas veikia tinklo paslaugos (web service) principu, todėl lengvai integruojamas į bet kokią sistemą bei gali veikti cloud ready sistemoje.
Video nuoroda: https://www.youtube.com/watch?v=MfRcnTpvHsA&t=190s